
Introduction
NVIDIA Inference Microservices (NIM) is a platform for managing and optimizing GPU-accelerated workloads, particularly in environments that are isolated from the internet, known as air-gapped environments. In such setups, NIM enables efficient deployment, monitoring, and scaling of AI and HPC workloads without internet access, ensuring security and compliance. Let’s see how to deploy NVIDIA NIMs in Air-Gapped Environment.
By managing all dependencies, model files, and container images locally, NIM allows organizations to fully utilize NVIDIA’s GPU technology for AI applications, even in highly secure, restricted environments.
Hardware / Software pre-req
1. Linux Server + The following
- At least 300 GB to 500GB of disk space.
- Stable internet connectivity.
- Docker: Installed and running .
- NVIDIA API Key: – see below
- NGC CLI Tool – see below
NVIDIA early access for NIMS
First step is to register NVIDIA NIM Early Access , Once registered we can download and use NIMS.
NOTE: API Keys are needed to download containers and models.
Step 1 – Prepare your connected environment
Below is a quick Diagram sketch , in this article we will focus on the Docker image & Model preparations. Data movement will be added as another blog post.
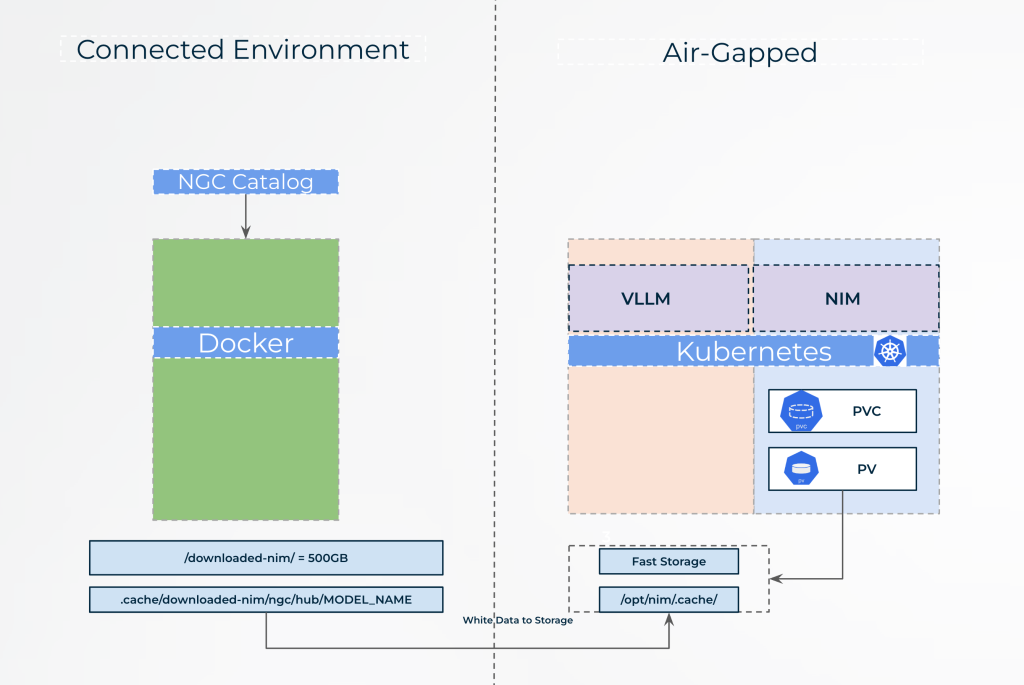
NOTE: You can install Kubernetes using Charmed Kubernetes in Production on Ubuntu
Once you have access and NVIDIA API KEY – we are ready! – Login NVIDIA registry using our new key.
Use the command below
kirson@nim-airgapped:~$ export NGC_API_KEY=navi-XXXXX
kirson@nim-airgapped:~$ echo "$NGC_API_KEY" | docker login nvcr.io --username '$oauthtoken' --password-stdin
WARNING! Your password will be stored unencrypted in /home/kirson/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credential-stores
Login Succeeded
Install the NGC CLI
kirson@nim-airgapped:~$ wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/ngc-apps/ngc_cli/versions/3.49.0/files/ngccli_linux.zip -O ngccli_linux.zip && unzip ngccli_linux.zip
#Confifgure ngc
./ngc-cli/ngc config set -
# List all available modes from NVIDIA
./ngc registry image list --format_type csv nvcr.io/nim/* > models.csv ; cat models.csv | csvlookList all available NIM modes from NVIDIA – Profiles not included
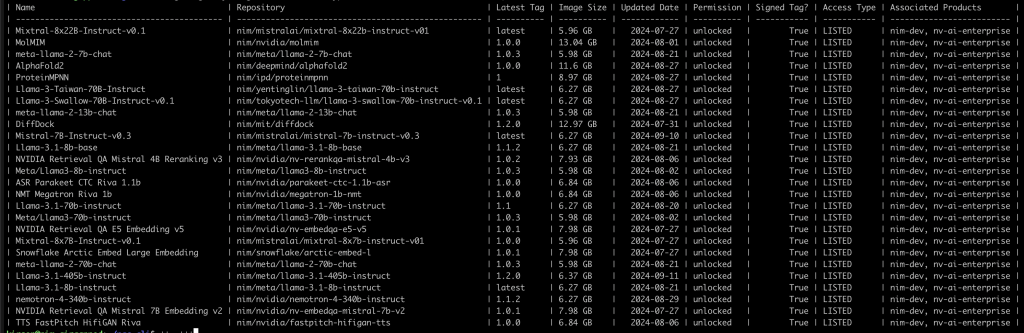
Prepare Docker using Local Storage
To run the NIM Large Language Model (LLM) in offline mode, start by setting up your environment and running the necessary Docker container. First, choose a name for your container, such as Llama-3.1-8B-instruct, and select the desired NIM image from the NVIDIA NGC registry. Define a local cache directory on your system to store the downloaded models, and make sure it has write permissions.
# Choose a container name for bookkeeping
export CONTAINER_NAME=Llama-3.1-8B-instruct
# The container name from the previous ngc registgry image list command
Repository=nim/meta/llama-3.1-8b-instruct
Latest_Tag=1.1.0
# Choose a LLM NIM Image from NGC
export IMG_NAME="nvcr.io/${Repository}:${Latest_Tag}"
# Choose a path on your system to cache the downloaded models
export LOCAL_NIM_CACHE=~/.cache/downloaded-nim
mkdir -p "$LOCAL_NIM_CACHE"
# Add write permissions to the NIM cache for downloading model assets
chmod -R a+w "$LOCAL_NIM_CACHE"
docker run -it --rm --name=$CONTAINER_NAME \
-e LOG_LEVEL=$LOG_LEVEL \
-e NGC_API_KEY=$NGC_API_KEY \
-v $LOCAL_NIM_CACHE:/opt/nim/.cache \
-u $(id -u) \
$IMG_NAME \
bash -iNOTE: You can add --gpus all to the docker command to see the default profile of your GPU card.
For more reference see NIM LLM Getting Started
Run the Docker container using the following command, which mounts your local cache directory to the container’s cache location:
Once inside the container, you can use the list-model-profiles command to view available model profiles. To download a specific profile, use the download-to-cache command followed by the profile ID. This method allows you to prepare and run your LLM models entirely offline, ensuring you have the necessary resources locally without requiring an active internet connection.
Example of “list-model-profile”
nim@6a986be24cc8:/$ list-model-profiles
INFO 09-16 07:41:04.529 info.py:23] Unable to get hardware specifications, retrieving every profile's info.
007a598b53ed150817bbc985982ff7141de64efc2ed3c9d8034b6d090dfb99d8: vllm-fp16-tp2-lora
0494aafce0df9eeaea49bbca6b25fc3013d0e8a752ebcf191a2ddeaab19481ee: tensorrt_llm-l40s-bf16-tp2-latency
0bc4cc784e55d0a88277f5d1aeab9f6ecb756b9049dd07c1835035211fcfe77e: tensorrt_llm-h100-fp8-tp2-latency
142ea46d5e2e26a4af2cd78e099cd601108302521e3ca41ae2a4ff91aba745b0: vllm-fp16-tp4
2959f7f0dfeb14631352967402c282e904ff33e1d1fa015f603d9890cf92ca0f: tensorrt_llm-h100-fp8-tp1-throughput
40543df47628989c7ef5b16b33bd1f55165dddeb608bf3ccb56cdbb496ba31b0: tensorrt_llm-h100-bf16-tp1-throughput-lora
581ad1a03318a658777921e94fd8929ff6947a5ae3868f01babc60a463c64364: vllm-fp16-tp4-lora
5d32170c5db4f5df4ed38a91179afda2396797c1a6e62474318e1df405ea53ce: vllm-fp16-tp1
6b89dc22ba60a07df3051451b7dc4ef418d205e52e19cb0845366dc18dd61bd6: tensorrt_llm-l40s-bf16-tp2-throughput-lora
7ea3369b85d7aee24e0739df829da8832b6873803d5f5aca490edad7360830c8: tensorrt_llm-a100-bf16-tp1-throughput
7f98797c334a8b7205d4cbf986558a2b8a181570b46abed9401f7da6d236955e: tensorrt_llm-h100-bf16-tp2-latency
9101fd55988cd727cb9d868fa2d946acad06a96b124c151958025ca938a10315: vllm-fp16-tp2
9cff0915527166b2e93c08907afd4f74e168562992034a51db00df802e86518c: tensorrt_llm-h100-bf16-tp1-throughput
a506c5bed39ba002797d472eb619ef79b1ffdf8fb96bb54e2ff24d5fc421e196: tensorrt_llm-a100-bf16-tp1-throughput-lora
a534b0f5e885d747e819fa8b1ad7dc1396f935425a6e0539cb29b0e0ecf1e669: tensorrt_llm-l40s-bf16-tp2-throughput
ba515cc44a34ae4db8fe375bd7e5ad30e9a760bd032230827d8a54835a69c409: tensorrt_llm-a10g-bf16-tp2-throughput
c5310764ae5b38a350559ada46d5f0a4cd2eb327f4b1f823c23dda3dc4a5ebc2: vllm-fp16-tp1-lora
d880feac6596cfd7a2db23a6bcbbc403673e57dec9b06b6a1add150a713f3fe1: tensorrt_llm-a100-bf16-tp2-latency
e42f68d5a600e7e528ee172ed4e88708a4c5b4623555ad69f30c3144f6bbea84: vllm-fp16-tp8-lora
e45b4b991bbc51d0df3ce53e87060fc3a7f76555406ed534a8479c6faa706987: tensorrt_llm-a10g-bf16-tp4-latency
e4e63a1f71d4f278ceaf03efce1abf4360c2b6df8d07756426c6331ccb043b6a: vllm-fp16-tp8
fcfdd389299632ae51e5560b3368d18c4774441ef620aa1abf80d7077b2ced2b: tensorrt_llm-a10g-bf16-tp4-throughput-lora
nim@6a986be24cc8:/$NOTE ! -> Each container has a different profile – for example running this command while loading nim/meta/llama-3.1-70b-instruct could provide a different results
Download profile to local disk
The Docker image uses your local hard drive directory to store downloaded model files. By mounting a local directory (e.g., ~/.cache/downloaded-nim) to the container’s internal cache location (/opt/nim/.cache), the container saves all model data directly to your system’s hard drive. This ensures that models are stored locally, allowing you later copy NIM LLM to the air-gapped env.
Example of “download-to-cache”
AS you can see we selected only one profile to download
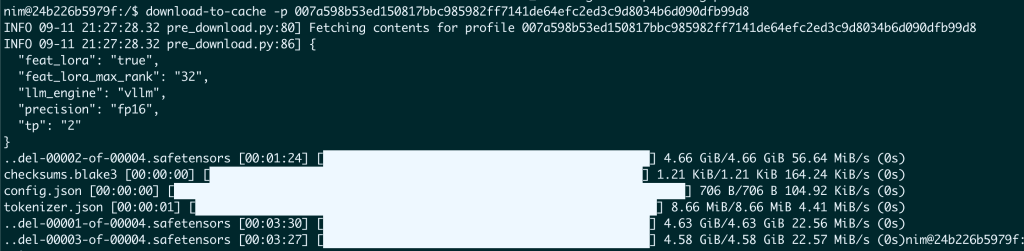
Once done – all files are located locally
/home/kirson/.cache/downloaded-nim/ngc/hub/models–nim–meta–llama-3_1-8b-instruct
Recap
Downloading NIM Modules from NVIDIA to a Connected Environment
In this post we’ve learned how to set up Large Language Model (LLM), or Profiles, in NVIDIA NIMs in Air-Gapped Environment. How to configure a local cache directory to store all the necessary models and data directly from NVIDIA’s NGC registry in a connected environment. This process ensures that the models are available locally, allowing for efficient offline use.
Next Steps: Copying Data to the Air-Gapped Environment
The next step is to transfer these downloaded model files from your connected environment to your air-gapped environment. This will enable you to run NIM LLM without internet access, maintaining data security and ensuring your models are ready for offline deployment.
I would like to Thanks Alex Volkov From NVIDIA – This Blog could not of been done without you
Alex Volkov is a Solutions Architect at NVIDIA. He works on the DGX solutions for the HPC developers and Data Scientists. Alex holds a MS in Electrical Engineering from Illinois Institute of Technology.





